scrapy基础实例,爬取zhipin网站信息
scarpy的新建 + scarpy模拟登录 + 在pipeline中存取信息到sqlite3 +xpath解析页面
- 文档
- 环境 python3.5.2 + scrapy1.3
scrapy新建工程
1 | scrapy startproject projectName |
具体可以查看 python3爬虫学习
发现 parse 或者 start_requests是爬虫的入口
解析html
scrapy支持xpath 和 css 两种选择器。这里使用xpath。
比如 这个页面 我们要获取页面上帖子的链接:
1 | ... |
这样就或获取到帖子的链接
递归
如何解析帖子链接的内容,并且递归到下一页呢?这里需要使用yield:
1 | yield scrapy.Request(url=url, callback=self.parse_page) |
scrapy会自行调度,并访问该url然后把内容拿回来
具体代码:
1 | class TestZhiPinSpider2(scrapy.Spider): |
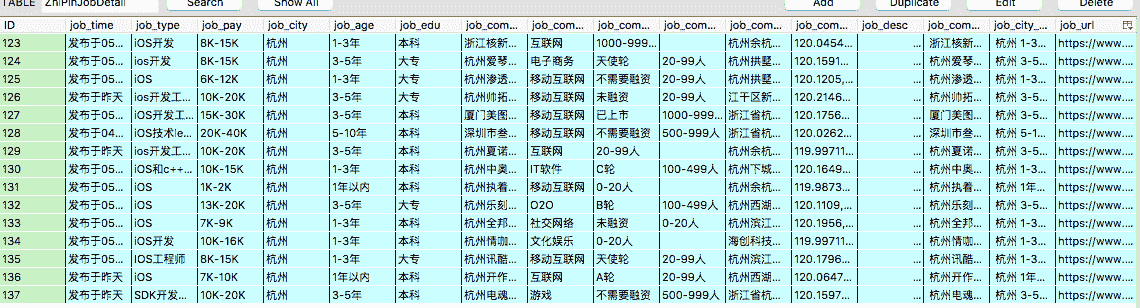
这个爬虫会将zhipin网站iOS招聘的信息都爬取一遍
Pipelines
可以看到新建工程后会生成一个pipelines.py的文件,可以在这里处理抓取的内容,存入数据库什么的。
1.在items.py中定义抓取的内容
这里简单写一个
1 | class TestJobDetailItem(Item): |
2.在pipelines中处理
在pipelines.py中新建Sqlite3Pipeline方法,原来可能有个FilePipeline不理它。
1 | from jobSpider.items import JobDetailItem |
这里例子详细写了将抓取数据写入数据库,这里用的是sqlite3。可以换成文件csv,mysql什么的。
3.在Setting中配置一下
找到settings.py 写入:
1 | #数据库信息 |
和
1 | # 配置pipeline |
这里可以配置多个pipeline,后面的数字表示优先级。scrapy会根据优先级,把item依次交给各个pipeline来处理。
4.在爬虫中调用这个pipeline
在上面递归例子中,加入 yield item
1 | from jobSpider.items import JobDetailItem |
scrapy会把这个item交给我们刚刚写的FilePipeline来处理.
登录
很多爬虫信息都要登录后才能抓取,这里也将登录模拟一遍,还是用 zhipin 网站。
使用zhipin网站的账号密码登陆模式
1 | # 测试登录 |
setting的一些配置
1 | # 间隔时间,单位秒。指明scrapy每两个请求之间的间隔。 |
最后
就可以爬取到所需要的招聘信息了: